MySQL Replication 是 MySQL 非常有特色的一个功能,他能够将一个 MySQL Server 的 Instance 中的数据完整的复制到另外一个 MySQL Server 的 Instance 中。虽然复制过程并不是实时而是异步进行的,但是由于其高效的性能设计,延时非常之少。MySQL 的 Replication 功能在实际应用场景中被非常广泛的用于保证系统数据的安全性和系统可扩展设计中。
MySQL Replication 实现原理
MySQL 的 Replication 是一个异步的复制过程,从一个 MySQL Instace(我们称之为 Master)复制到另一个 MySQL Instance(我们称之 Slave)。在 Master 与 Slave 之间的实现整个复制过程主要由三个线程来完成,其中两个线程 (SQL 线程和 IO 线程) 在 Slave 端,另外一个线程(IO 线程)在 Master 端。
要实现 MySQL 的 Replication,首先必须打开 Master 端的 Binary Log(mysql-bin.xxxxxx)功能,否则无法实现。因为整个复制过程实际上就是 Slave 从 Master 端获取该日志然后再在自己身上完全顺序的执行日志中所记录的各种操作。打开 MySQL 的 Binary Log 可以通过在启动 MySQL Server 的过程中使用 —log-bin 参数选项,或者在 my.cnf 配置文件中的 mysqld 参数组([mysqld]标识后的参数部分)增加 log-bin 参数项。
MySQL 复制的基本过程如下:
Slave 上面的 IO 线程连接上 Master,并请求从指定日志文件的指定位置(或者从最开始的日志)之后的日志内容;
Master 接收到来自 Slave 的 IO 线程的请求后,通过负责复制的 IO 线程根据请求信息读取指定日志指定位置之后的日志信息,返回给 Slave 端的 IO 线程。返回信息中除了日志所包含的信息之外,还包括本次返回的信息在 Master 端的 Binary Log 文件的名称以及在 Binary Log 中的位置;
Slave 的 IO 线程接收到信息后,将接收到的日志内容依次写入到 Slave 端的 Relay Log 文件(mysql-relay-bin.xxxxxx)的最末端,并将读取到的 Master 端的 bin-log 的文件名和位置记录到 master-info 文件中,以便在下一次读取的时候能够清楚地告诉 Master “我需要从某个 bin-log 的哪个位置开始往后的日志内容,请发给我”;
Slave 的 SQL 线程检测到 Relay Log 中新增加了内容后,会马上解析该 Log 文件中的内容成为在 Master 端真实执行时候的那些可执行的 Query 语句,并在自身执行这些 Query。这样,实际上就是在 Master 端和 Slave 端执行了同样的 Query,所以两端的数据是完全一样的。
MySQL Replication 常用架构
MySQL Replicaion 本身是一个比较简单的架构,就是一台 MySQL 服务器(Slave)从另一台 MySQL 服务器(Master)进行日志的复制然后再解析日志并应用到自身。一个复制环境仅仅只需要两台运行有 MySQLServer 的主机即可,甚至更为简单的时候我们可以在同一台物理服务器主机上面启动两个 mysqldinstance ,一个作为 Master 而另一个作为 Slave 来完成复制环境的搭建。但是在实际应用环境中,我们可以根据实际的业务需求利用 MySQL Replication 的功能自己定制搭建出其他多种更利于 Scale Out 的复制架构。如 Dual Master 架构,级联复制架构等。下面我们针对比较典型的三种复制架构进行一些相应的分析介绍。
常规复制架构 Master – Slaves
在实际应用场景中, MySQL 复制90%以上都是一个 Master 复制到一个或者多个 Slave 的架构模式,主要用于读压力比较大的应用的数据库端廉价扩展解决方案。因为只要 Master 和 Slave 的压力不是太大(尤其是 Slave 端压力)的话,异步复制的延时一般都很少很少。尤其是自从 Slave 端的复制方式改成两个线程处理之后,更是减小了 Slave 端的延时问题。而带来的效益是,对于数据实时性要求不是特别 Critical 的应用,只需要通过廉价的 PC server 来扩展 Slave 的数量,将读压力分散到多台 Slave 的机器上面,即可通过分散单台数据库服务器的读压力来解决数据库端的读性能瓶颈,毕竟在大多数数据库应用系统中的读压力还是要比写压力大很多。这在很大程度上解决了目前很多中小型网站的数据库压力瓶颈问题,甚至有些大型网站也在使用类似方案解决数据库瓶颈。
这个架构可以通过下图比较清晰的展示:
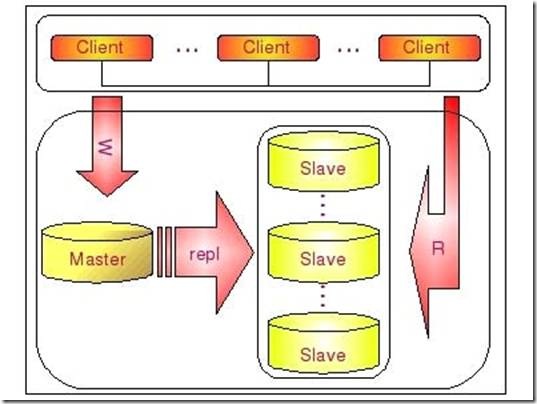
一个 Master 复制多个 Slave 的架构实施非常简单,多个 Slave 和单个 Slave 的实施并没有实质性的区别。在 Master 端并不Care 有多少个 Slave 连上了自己,只要有 Slave 的 IO 线程通过了连接认证,向他请求指定位置之后的 Binary Log 信息,他就会按照该 IO 线程的要求,读取自己的 Binary Log 信息,返回给 Slave 的 IO 线程。
大家应该都比较清楚,从一个 Master 节点可以复制出多个 Slave 节点,可能有人会想,那一个 Slave 节点是否可以从多个 Master 节点上面进行复制呢?至少在目前来看,MySQL 是做不到的,以后是否会支持就不清楚了。
MySQL 不支持一个 Slave 节点从多个 Master 节点来进行复制的架构,主要是为了避免冲突的问题,防止多个数据源之间的数据出现冲突,而造成最后数据的不一致性。不过听说已经有人开发了相关的 patch ,让 MySQL 支持一个 Slave 节点从多个 Master 结点作为数据源来进行复制,这也正是 MySQL 开源的性质所带来的好处。
Dual Master 复制架构 Master – Master
有些时候,简单的从一个 MySQL 复制到另外一个 MySQL 的基本 Replication 架构,可能还会需要在一些特定的场景下进行 Master 的切换。如在 Master 端需要进行一些特别的维护操作的时候,可能需要停 MySQL 的服务。这时候,为了尽可能减少应用系统写服务的停机时间,最佳的做法就是将我们的 Slave 节点切换成 Master 来提供写入的服务。
但是这样一来,我们原来 Master 节点的数据就会和实际的数据不一致了。当原 Master 启动可以正常提供服务的时候,由于数据的不一致,我们就不得不通过反转原 Master-Slave 关系,重新搭建 Replication 环境,并以原 Master 作为 Slave 来对外提供读的服务。重新搭建 Replication 环境会给我们带来很多额外的工作量,如果没有合适的备份,可能还会让 Replication 的搭建过程非常麻烦。
为了解决这个问题,我们可以通过搭建 Dual Master 环境来避免很多的问题。何谓 Dual Master 环境?实际上就是两个 MySQL Server 互相将对方作为自己的 Master,自己作为对方的 Slave 来进行复制。这样,任何一方所做的变更,都会通过复制应用到另外一方的数据库中。
下如将更清晰的展示DualMaster复制架构组成:
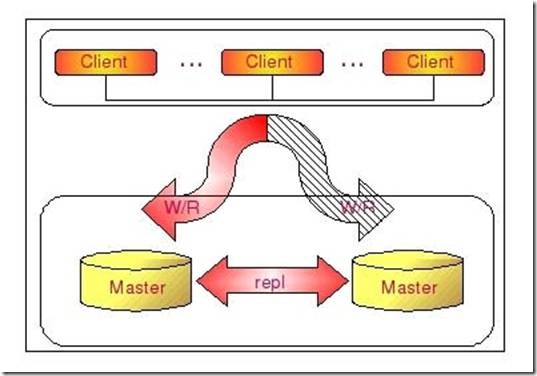
通过 Dual Master 复制架构,我们不仅能够避免因为正常的常规维护操作需要的停机所带来的重新搭建 Replication 环境的操作,因为我们任何一端都记录了自己当前复制到对方的什么位置了,当系统起来之后,就会自动开始从之前的位置重新开始复制,而不需要人为去进行任何干预,大大节省了维护成本。
不仅仅如此,Dual Master 复制架构和一些第三方的 HA 管理软件结合,还可以在我们当前正在使用的 Master 出现异常无法提供服务之后,非常迅速的自动切换另外一端来提供相应的服务,减少异常情况下带来的停机时间,并且完全不需要人工干预。
级联复制架构 Master – Slaves – Slaves
在有些应用场景中,可能读写压力差别比较大,读压力特别的大,一个 Master 可能需要上10台甚至更多的 Slave 才能够支撑注读的压力。这时候,Master 就会比较吃力了,因为仅仅连上来的 Slave IO 线程就比较多了,这样写的压力稍微大一点的时候,Master 端因为复制就会消耗较多的资源,很容易造成复制的延时。
遇到这种情况如何解决呢?这时候我们就可以利用 MySQL 可以在 Slave 端记录复制所产生变更的 Binary Log 信息的功能,也就是打开 —log-slave-update 选项。然后,通过二级(或者是更多级别)复制来减少 Master 端因为复制所带来的压力。也就是说,我们首先通过少数几台 MySQL 从 Master 来进行复制,这几台机器我们姑且称之为第一级 Slave 集群,然后其他的 Slave 再从第一级 Slave 集群来进行复制。从第一级 Slave 进行复制的 Slave ,我称之为第二级 Slave 集群。如果有需要,我们可以继续往下增加更多层次的复制。这样,我们很容易就控制了每一台 MySQL 上面所附属 Slave 的数量。这种架构我称之为 Master – Slaves – Slaves 架构。
这种多层级联复制的架构,很容易就解决了 Master 端因为附属 Slave 太多而成为瓶颈的风险。下图展示了多层级联复制的 Replication 架构。
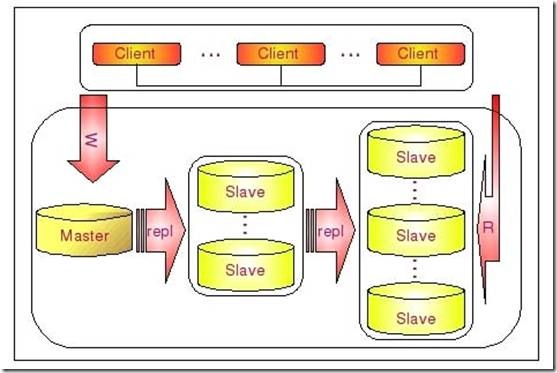
当然,如果条件允许,我更倾向于建议大家通过拆分成多个 Replication 集群来解决。
上述瓶颈问题。毕竟 Slave 并没有减少写的量,所有 Slave 实际上仍然还是应用了所有的数据变更操作,没有减少任何写 IO 。相反,Slave 越多,整个集群的写 IO 总量也就会越多,我们没有非常明显的感觉,仅仅只是因为分散到了多台机器上面,所以不是很容易表现出来。
此外,增加复制的级联层次,同一个变更传到最底层的 Slave 所需要经过的 MySQL 也会更多,同样可能造成延时较长的风险。
Dual Master 与级联复制结合架构(Master-Master-Slaves)
级联复制在一定程度上面确实解决了 Master 因为所附属的 Slave 过多而成为瓶颈的问题,但是他并不能解决人工维护和出现异常需要切换后可能存在重新搭建 Replication 的问题。这样就很自然的引申出了 Dual Master 与级联复制结合的 Replication 架构,我称之为 Master-Master-Slaves 架构
和 Master-Slaves-Slaves 架构相比,区别仅仅只是将第一级 Slave 集群换成了一台单独的 Master ,作为备用 Master ,然后再从这个备用的 Master 进行复制到一个 Slave 集群。下面的图片更清晰的展示了这个架构的组成:
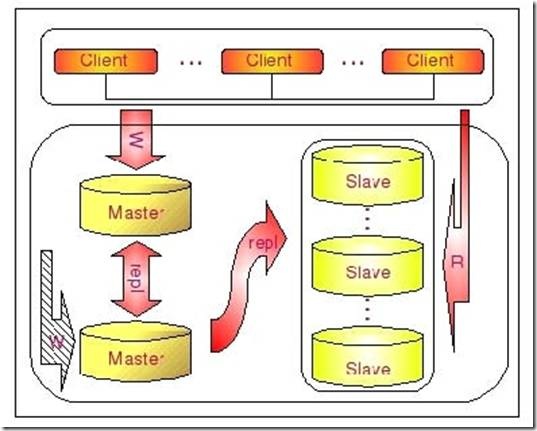
这种 Dual Master 与级联复制结合的架构,最大的好处就是既可以避免主 Master 的写入操作不会受到 Slave 集群的复制所带来的影响,同时主 Master 需要切换的时候也基本上不会出现重搭 Replication 的情况。但是,这个架构也有一个弊端,那就是备用的 Master 有可能成为瓶颈,因为如果后面的 Slave 集群比较大的话,备用 Master 可能会因为过多的 Slave IO 线程请求而成为瓶颈。当然,该备用 Master 不提供任何的读服务的时候,瓶颈出现的可能性并不是特别高,如果出现瓶颈,也可以在备用 Master 后面再次进行级联复制,架设多层 Slave 集群。当然,级联复制的级别越多,Slave 集群可能出现的数据延时也会更为明显,所以考虑使用多层级联复制之前,也需要评估数据延时对应用系统的影响。
Have a nice day!